Emu Edit: Precise Image Editing via Recognition and Generation Tasks
We present Emu Edit, a multi-task image editing model which sets a new state-of-the-art in instruction-based image editing. To develop Emu Edit we adapt its architecture for multi-task learning and train it an unprecedented range of tasks, such as region-based editing, free-form editing, and computer vision tasks such as detection and segmentation - all formulated as generative tasks.
Emu Edit in Action
Approach
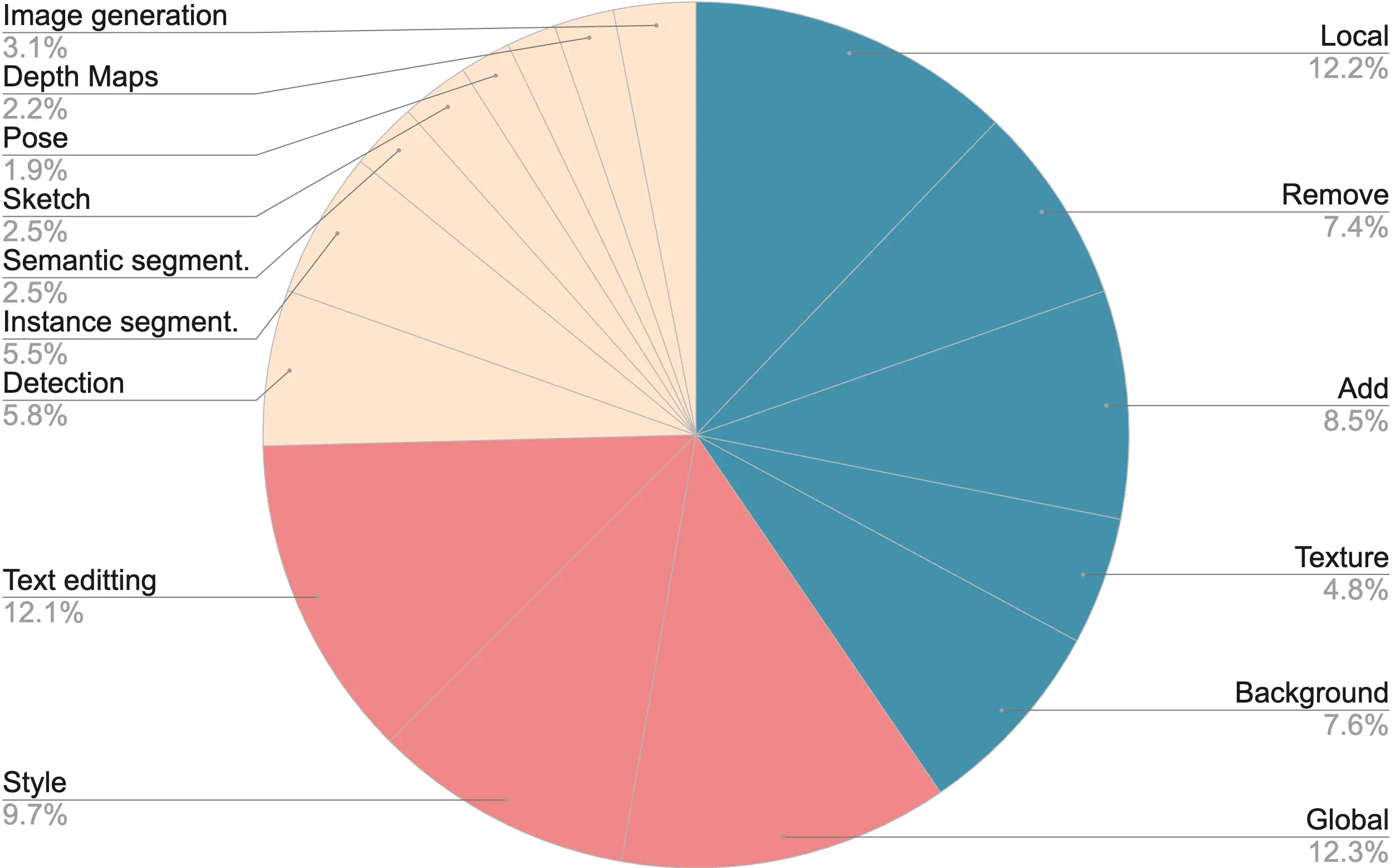
In order to create a robust and accurate image editing model we train Emu Edit to multi-task across a wide range of image editing tasks. These tasks span region-based editing tasks, free-form editing tasks, computer vision tasks, and more, all formulated as generative tasks. Additionally, to process this wide array of tasks effectively, we introduce the concept of learned task embeddings, which are used to steer the generation process toward the correct generative task. We demonstrate that both multi-task training, and utilizing learned task embeddings significantly enhance the ability of our model to accurately execute the editing instruction.
Few-Shot Learning
Equipped with a robust model trained across a broad spectrum of tasks and guided by learned task embeddings, we explore few-shot adaptation to unseen tasks via task inversion. In this process, we keep the model weights frozen, and solely update a task embedding to fit the new task. Our experiments demonstrate that Emu Edit can swiftly adapt to new tasks, such as super-resolution, contour detection, and others. This makes task inversion with Emu Edit particularly advantageous in scenarios where labeled examples are limited, or when the compute budget is low.




Benchmark
To support rigorous and informed evaluation of instruction-based image editing models we collect and publicly release a new benchmark that includes seven different image editing tasks: background alteration (background), comprehensive image changes (global), style alteration (style), object removal (remove), object addition (add), localized modifications (local), and color/texture alterations (texture) Additionally, to allow proper comparison against Emu Edit, we release Emu Edit’s generations on the dataset.
Authors
Acknowledgements
We extend our gratitude to the following people for their contributions (alphabetical order): Andrew Brown, Ankit Ramchandani, Guan Pang, Ishan Misra, Mannat Singh, Ning Zhang, Parveen Krishnan, Peizhao Zhang, Peter Vajda, Rohit Girdhar, Roshan Sumbaly, Tong Xiao, Vladan Petrovic, Xide Xia.
Citation
@inproceedings{Sheynin2023EmuEP,
title={Emu Edit: Precise Image Editing via Recognition and Generation Tasks},
author={Shelly Sheynin and Adam Polyak and Uriel Singer and Yuval Kirstain and Amit Zohar and Oron Ashual and Devi Parikh and Yaniv Taigman},
year={2023},
url={https://api.semanticscholar.org/CorpusID:265221391}
}